
多くの企業は、重要なビジネスデータを非構造化ドキュメントで保存しています。たとえば、賃貸契約書には、物件情報、賃貸条件、テナント名などの重要な詳細が記載されています。このデータを手動で抽出する作業は非効率的で、大規模に行うことは困難です。
この記事では、Box AI、Airbyte、MotherDuck (DuckDB) を使用して、賃貸契約書からの構造化データ抽出を自動化する概念的なソリューションについて説明します。
ソリューションの概要
この概念的なソリューションにより、企業は、賃貸契約書から構造化データを抽出して照会可能なデータベースに保存できます。このワークフローは以下で構成されます。
- Box AI: AIによる構造化データの抽出エンドポイントを使用して、賃貸契約書から構造化データを抽出する
- Airbyte: 抽出したデータをBox AIからデータベースに移動する
- MotherDuck: 簡単に照会できるように、構造化データをオンラインのDuckDBインスタンスに保存する
BoxのAirbyteコネクタの役割
このプロセスを容易にするために、Box APIを介してBox AIを操作する「Box Data Extract」というAirbyteソースコネクタを作成しました。
このデモでは主にAIによる構造化データの抽出エンドポイントを使用しますが、このコネクタは以下もサポートしています。
- AIへの質問: 要約および要点の抽出用 (このデモでは使用しません)
- AIによる自由形式での抽出: 自由形式のテキストを使用してドキュメントからデータを抽出する
- テキストレプリゼンテーション: ドキュメントを読み取り可能なテキストに変換する
Boxに保存されている賃貸契約書
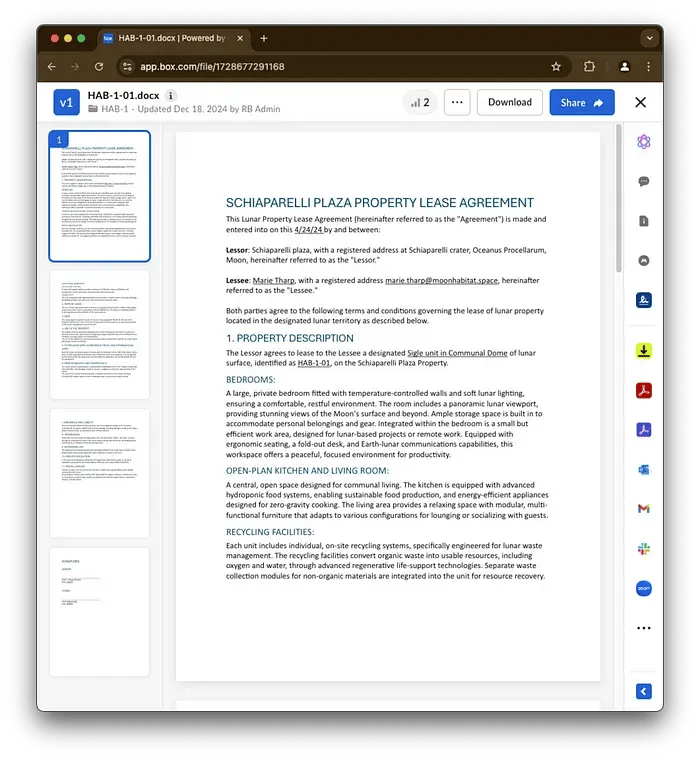
賃貸契約書のサンプル
場所を除けば、これはほぼ標準的な賃貸契約書です。私たちが探している情報は、物件の種類、賃貸期間の開始日と終了日、契約日、賃借人の名前とメールアドレス、物件の場所、月額賃料、寝室数です。
通常、このタイプのドキュメントでは、情報が契約条項全体に分散しています。
Box AIの最大の特徴の1つは、ドキュメント形式のバリエーションに対応できることです。
AIはドキュメントのコンテキストを「理解」するため、表示される形式や資料が異なる場合でも、特定の情報を見つけることができます。
精度を向上させるために、ユーザーは、抽出された各フィールドにプロンプトのヒントを設定し、関連する詳細をAIが特定できるように導くことが可能です。
Airbyteパイプライン
Airbyte側では、Box Data Extractソースを使用して情報をMotherDuckの保存先に送信するようデータパイプラインを構成します。
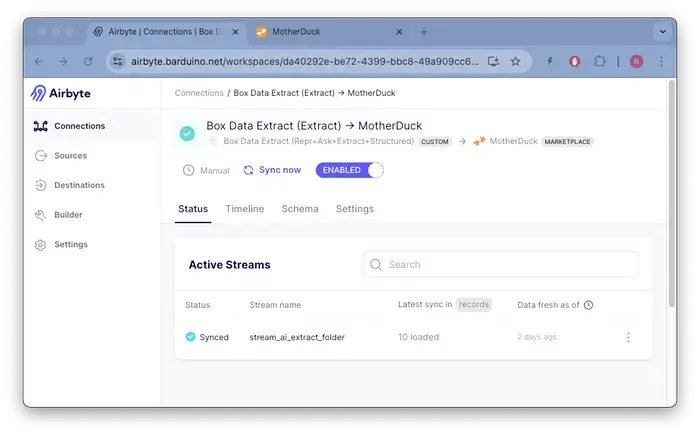
Airbyteデータパイプライン
ソースの構成は次のように設定します。
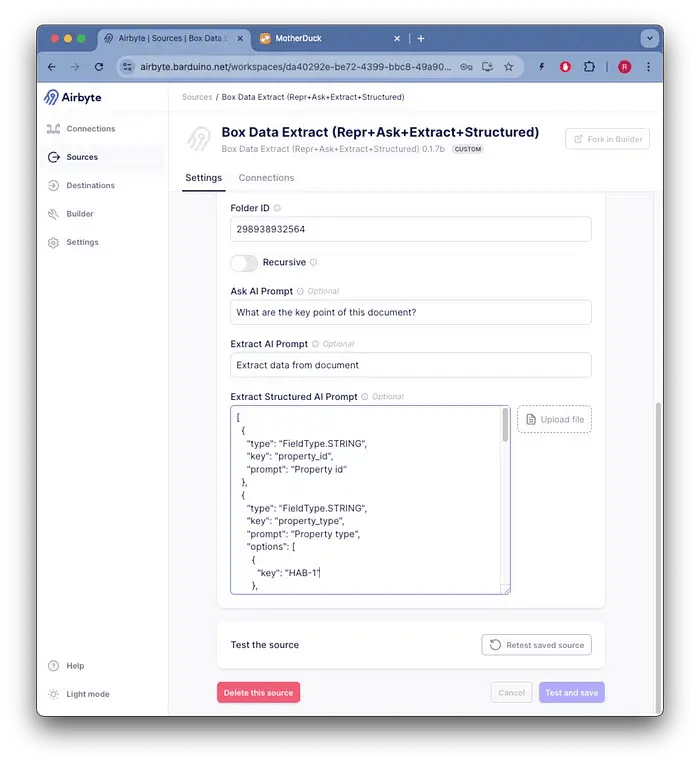
Box Data Extractソースの構成
ドキュメント内で探す情報を指定するために使用されるJSONスキーマに注意してください。AIが情報を見つけるのに役立つ各フィールドの特定のプロンプトが含まれています。
MotherDuckの保存先の構成は、APIキーの設定と同じように簡単です。
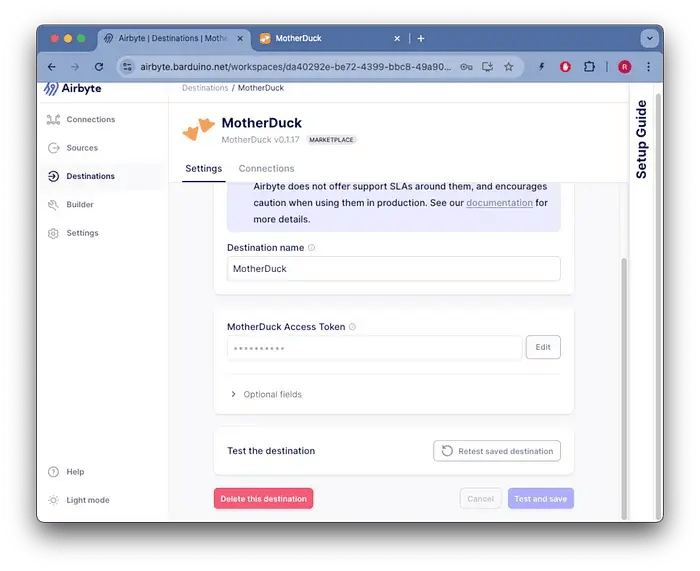
MotherDuckの保存先の構成
MotherDuckデータベース
Airbyteでデータパイプラインを実行すると、MotherDuck DuckDBにテーブルが自動的に作成されます。
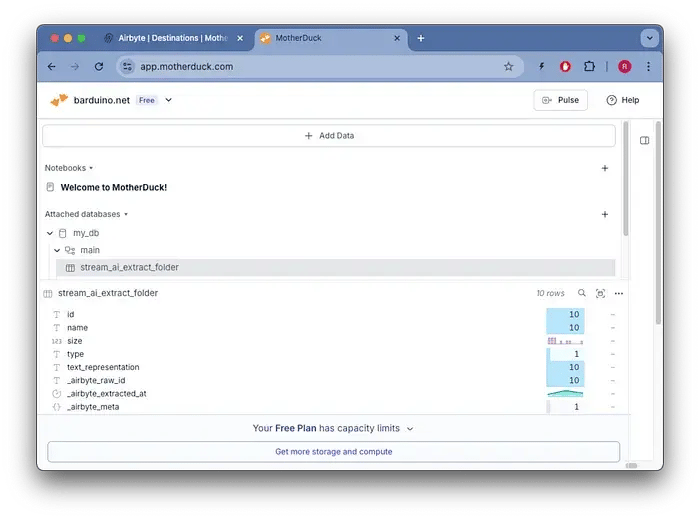
MotherDuck DuckDBで作成されたテーブル
ここから、簡単にテーブルを照会できます。
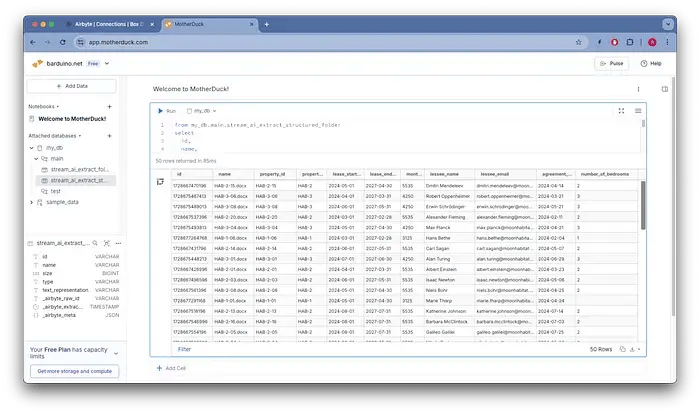
DuckDBテーブルに対するSQLクエリの結果
パフォーマンスと自動化
テスト時に、システムは約4分間で50件の賃貸契約書を処理しました。十分なベンチマークではありませんが、このアプローチの潜在的な効率性を示しています。人間が1件の契約書を読むには4分では足りず、まして50件も読むことはできません。
Airbyte側では、このプロセスはスケジュールに従って自動的に開始することも、必要に応じて手動で開始することも可能です。
データ品質の確保とベストプラクティス
AIが生成したデータにはエラーや根拠のない情報が含まれている可能性があることを考えると、抽出されたデータを確認する必要があります。企業は、意思決定にデータを利用する前にデータの一貫性を検証するメカニズムを実装する必要があります。
賃貸契約書以外への拡大
このデモでは賃貸契約書に焦点を当てていますが、以下のような幅広いドキュメントタイプに同じ手法を適用できます。
- 請求書: ベンダーの詳細、請求書番号、支払い条件、支払い額を抽出する
- その他の契約書: 当事者、契約期間、主要条項、義務を特定する
- 会計報告書: 収益、経費、利益率、財務諸表を抽出する
- 人事ドキュメント: 従業員の契約書、福利厚生情報、コンプライアンス記録を解析する
- 保険金請求書: 保険証券番号、請求額、補償内容の詳細を抽出する
- 規制当局への提出書類: コンプライアンスドキュメントや規制報告書の処理を自動化する
抽出された構造化データにより、以下のような複数のビジネスプロセスを強化できます。
- 自動化ワークフロー: 抽出されたデータにより、請求書の承認、契約更新、コンプライアンスチェックなどの操作を開始する
- 顧客関係管理 (CRM): エンゲージメント向上のために、契約書やフォームなどのドキュメントからの顧客の詳細をCRMプラットフォームに統合する
- 規制順守とKYC: コンプライアンスチェックの自動化、身元確認、法的要件への順守の確認を行う
- 企業資源計画 (ERP) システム: 構造化された財務データと運用データをERPアプリケーションに入力する
- 財務分析と財務報告: 財務報告と傾向分析を自動化する
- 契約リスク評価: AIは、抽出したデータを標準的な契約書と比較することで、一般的でない条件、欠落している条項、または潜在的な法的責任を含む契約にフラグを設定する
まとめ
このデモでは、Box AI、Airbyte、MotherDuckを使用して賃貸契約書から構造化データを抽出する作業のシンプルさと効果に焦点を当てて説明しました。
非構造化ドキュメントを照会可能な構造化データに変換する機能により、さまざまな自動化と統合の可能性が広がります。
企業は、最小限の設定で、ドキュメントに基づくワークフローを効率化し、組織全体でデータアクセシビリティを向上させることができます。