

Image generated by deep ai
この記事では、Box AIとDoc Gen APIを使用してワークフローを効率化し、構造化されていない映画脚本を最小限の労力で実用的なインサイトに変換する方法について説明します。
はじめに
あなたが映画制作会社で働いていて、すべてのドキュメントとコンテンツの保存にBoxを使用していると想像してください。
プロデューサーのアシスタントは、毎月、数十本の映画脚本を受け取り、主な脚本の詳細を要約した社内メモを作成する必要があります。
従来、この手動によるタスクは面倒で時間がかかります。しかし、このタスクをAIで自動化できるとしたらどうでしょうか。
ワークショップ: AIを活用した自動化の実践
このワークショップは、経験レベルに関係なく開発者が利用できるように、シンプルさを念頭に置いて設計されました。以下が用意されています。
- Box SDKを使用した実践的なPythonソリューション
- テストを容易にするための事前に構成されたサンプルスクリプト
- 参加者が変更および検証するための全面的にカスタマイズ可能なコード
このワークショップを終了すると、以下のことが可能になります。
✅ Box AI extractおよび質問エンドポイントの使用方法を理解する
✅ Box Doc Genの使用経験を得る
✅ 今後の参考用のPythonプロジェクトを入手する
こちらのGitHubリポジトリに着手しましょう。
ユースケース: 映画脚本から要約の作成
ある制作会社が送られてくる脚本の確認を任されていると想像してみてください。脚本ごとに、以下の内容を含む社内メモが必要になります。
- 基本的な詳細 (タイトル、日付、ジャンル、著者)
- プロットの要約
- 場所や小道具の説明
- 俳優の候補を含む登場人物のリスト
- 監督とプロデューサーの推薦
- 著者の背景情報 (過去の作品、制作史、収益インサイト)
この情報を手作業でまとめるのは、手間がかかるうえに反復的な作業となります。その解決方法として、Box AIを使用して、この構造化データを自動的に抽出して生成できます。
Box AIとDoc Genでプロセスを自動化する方法
このワークショップでは、2つの主要なBox AI機能を使用して、映画脚本の分析を自動化する実践的なPythonベースの手法を紹介します。
映画脚本からデータを抽出する
Box AI extractエンドポイントを使用すると、開発者は、明確に定義されたJSONスキーマを提供できます。その後、Box AIは、映画脚本をスキャンし、関連する詳細をJSON形式で入力します。
これは、次のように簡単です。
いくつかの優れたライブラリを使用することで、Pythonデータクラスであるclass Scriptから直接JSONスキーマを抽出していることに注目してください。
Pythonデータクラスのメタデータプロパティを使用して、情報の取得方法についてAIにヒントを与えることができます。次に例を示します。
脚本を超えたインサイトを生成する
俳優や監督の提案など、必要な情報の中には脚本に含まれていないものもあります。そこで役に立つのがBox AIの質問エンドポイントです。リクエストの書式を適切に設定することで、AIが生成した推奨事項をJSON形式で取得できます。
たとえば、登場人物のリストを取得するには、映画脚本を読み取り、それぞれの役に提案する俳優をAIに質問する必要があります。
上記のサンプルデータは次のようになります。
出力結果は次のようになります。
社内メモを作成する
Box AIによって必要なデータが抽出および生成されたら、Box Doc Gen APIを使用して、そのデータの書式を意思決定のための構造化されたメモに整えます。
まず、MS Wordテンプレートが必要です。このテンプレートに含まれる特殊なタグは、テンプレートをデータとマージする際に置き換えられます。
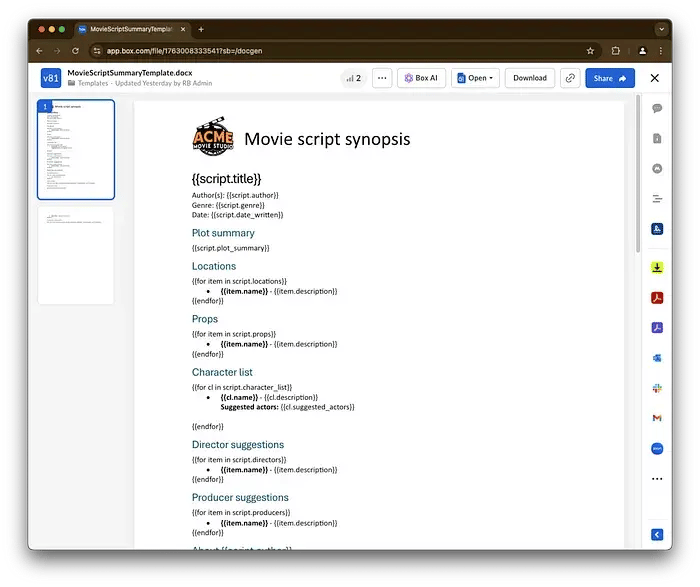
使用するテンプレート
Box Doc Gen APIは、構造化されたJSONデータを受け取り、事前定義されたドキュメントテンプレートにマージします。これにより、プロデューサーがすぐに確認できる、整った社内メモを作成できます。
以下に、データのサンプルを示します。
テンプレートとデータのマージもわかりやすくシンプルです。ワークショップのサンプルを以下に示します。
上記のサンプルにより、Doc Genのバッチが作成され、次のようなPDFが出力されます。
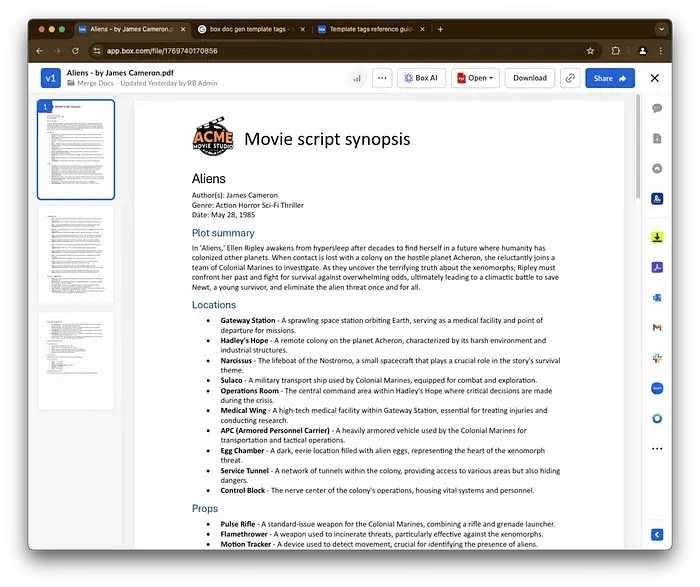
生成されたPDF
ワークフローを自動化する
自動化は、以下の複数の方法でトリガーできます。
- Webhookにより、指定したBoxフォルダ内で新しい脚本のアップロードを検出します。
- Boxウェブアプリ内の手動アクションにより、ユーザーは処理を開始できます。
- Box Skill統合により、既存のワークフローへのシームレスな埋め込みが可能になります。
開発者は、このソリューションをBox内で自己完結させることも、サードパーティのデータソースを統合して拡張することもできます。
主な習得事項と考慮事項
以下に、この概念実証の構築中に得られた知見をいくつか紹介します。
🔹 AIの制限事項への対処: AIは詳細の一部を抽出できない場合があるため、開発者は欠落したデータを考慮する必要があります。
🔹 事実確認が不可欠: LLMモデルだけに頼るのは危険です。検証には複数のソースを使用してください。
🔹 データの形式が重要: Doc Genに提供されたJSONはできるだけフラットにする必要があります。入れ子になったリストはサポートされません。
🔹 スクリプトサイズの制約: 一部のスクリプトは、Box AIで効率的に処理するには大きすぎました。
🔹 Pythonで簡単に: Box Python SDKにより、わずか数行のコードでこの自動化が可能になります。
まとめ: AIを活用したドキュメントの自動化の実現
このワークショップは、単に技術を紹介するデモではなく、不可能なことは追い求めずに実現できることを実行する技術の探求を提案しています。この例では映画脚本に焦点を当てていますが、業界を超えて同じ原則を当てはめることができ、契約書、財務報告書、研究論文のいずれを扱う場合でも、Box AIとDoc Genにより、構造化されていないコンテンツを構造化された実用的なインサイトに変換できます。
ワークフローの自動化に関心をお持ちの方は、こちらのワークショップをお試しいただき、Box AIとDoc Genで何ができるかを再考してみてください。🚀