
構造化メタデータは、Boxにおいて最も強力なレイヤーの1つで、検索、フィルタ、リテンションポリシー、自動化、ダウンストリームワークフローを支える基盤となっています。Box AIを使用すると、請求書、契約書、フォームなどの非構造化ドキュメントから直接その構造を抽出し、繰り返しファイルに適用できます。
この記事では、まさにその処理を実行する小さなPython CLIを作成します。このCLIは、Boxからファイルを読み取り、Box AIの抽出 (構造化) を使って既知の一連のフィールドを抽出し、それらの値をBoxメタデータとして書き戻します。
ここで興味深いのはCLIそのものではありません。ワークフローがどのように定義され、実現されるかです。
今回は、数多くの非常に細かいプロンプトを使用して実装を推進するのではなく、開発者とAIコーディングアシスタント間の契約として機能する、単一のリポジトリアーティファクトであるagents.mdを利用します。
作成する機能
ここでの目的は、CLIを新たに記述することではありません。その代わり、メタデータ抽出ワークフロー全体を実行する具体的な方法として、小さなPython CLIを使用します。
CLI自体は意図的にシンプルになっています。これは、Boxからファイルを読み取り、Box AIの抽出 (構造化) を使ってあらかじめ定義された一連のフィールドを抽出し、それらの値をBoxメタデータとしてファイルに書き戻すといった繰り返し可能なフローを調整するために存在します。
プロジェクトの準備が整ったら、リポジトリのルートからワークフローを実行できます。次に例を示します。
実際には、これにより、CLIにドキュメント (一連の請求書) のフォルダを指定し、基になる同じロジックを使用してすべてのファイルからメタデータを抽出して書き戻すことができます。この記事の残り部分では、各コード行を手動で記述することではなく、そのワークフローがどのように定義され、実現されるかに焦点を当てます。
agents.mdを使用する理由
AIコーディングツールを使ったことがある方なら、出力の品質はプロンプトの巧妙さよりも制約の明確さに左右されることに気づいていることでしょう。
agents.mdファイルは、これらの制約をリポジトリ自体に含めるための簡単な手段で、チャットを開くたびに制約を説明し直す必要がなくなります。このファイルは、プロジェクトの実行内容、プロジェクトの構成、許可されていること、「完了」が表す状態を説明する、人間が判読できる軽量な仕様書のようなものと考えてください。
このプロジェクトのagents.mdでは、想定されるCLIインターフェース、認証方法、使用する必要のあるSDKインポートパス、さらには、CLIが正常に実行された場合に表示される正確な一連の出力を定義しています。これにより、プロンプトは抽象的なレベルを維持しつつ、具体的な内容は本来あるべき場所にコードと共に配置されます。
このチュートリアルに従うためにagents.mdを採用する必要はありません。重要なのはその背後にある考え方です。つまり、リポジトリがそれ自体の構造や制約を明確に定義していると、AIを使用した開発は、ますます予測可能になり、レビューや拡張も簡単になります。
アーキテクチャの概要
大まかに言うと、ワークフローは次のようになります。
CLIは主に調整役です。真の価値は、抽出→正規化→メタデータ書き込みを安定した基本処理として扱い、それ以外は極力シンプルに保つことにあります。
前提条件
始める前に、以下が必要です。
- クライアント資格情報許可 (CCG) 用に構成されたBoxアプリ。このアプリは、処理するコンテンツ (Enterprise設定/スコープ) にアクセスできます
- 企業全体でBox AIが有効になっていること
- Box内のメタデータテンプレート (つまり、入力したいスキーマ)
これまでにメタデータテンプレートを使用したことがない場合、テンプレートは、Box AIで抽出するフィールドのスキーマと考えてください。
テストのために、代表的なドキュメント (請求書、領収書、契約書など) がいくつか入っているフォルダを用意しておくと、一貫した出力を確認できます。
出発点: agents.md
最初はリポジトリを意図的に最小限にしています。まだ枠組みもPythonパッケージもCLIコードもありません。意味のあるアーティファクトはまさにagents.mdだけです。
そのファイルは、プロジェクト全体の信頼できるソースとして機能します。プロンプトで実装を段階的に記述するのではなく、実行ごとに変化しない決定事項 (つまり、コードを生成または修正するたびに毎回説明し直すことになるような事項) が保存されています。
具体的に、agents.mdには以下のような詳細を明記しています。
- 使用する必要のあるSDK (box-sdk-gen)
- 認証モデル (CCG、環境変数を使用)
- CLIの呼び出し方法 (python -m src.cli run ...)
- プロジェクトの構造 (存在するファイル、各ファイルが所有する内容)
- Box AI抽出 (構造化) のための正確なスキーマインポート (避けるべきインポートを含む)
このような制約こそが、このワークフローの他の部分を予測可能にしています。コーディングアシスタントは曖昧な説明から構造を推測しているのではなく、コードとともに存在する仕様を実装しているのです。
agents.mdの完成版はこちらのリポジトリで公開されていますが、一行ずつ読む必要はありません。重要なのは、この時点でそれが唯一の出発点となる入力であり、完成した実行可能なプロジェクトを生成するのに十分に具体的であるということです。
1つのプロンプトを実行する
agents.mdの準備が整ったら、コーディングアシスタントに対して、次のように1つの指示を出します。
以上です。
プロンプトが短いのは、目的と制約がすでにリポジトリにエンコードされているためです。ファイル名やモジュールの境界、CLIフラグ、さらには扱いにくいSDKインポートパスまでも、すでに決定事項としてagents.mdにエンコードされているため、明記する必要はありません。アシスタントは「私の言いたいことを推測している」のではなく、コードのすぐ側にある仕様を実装しているのです。
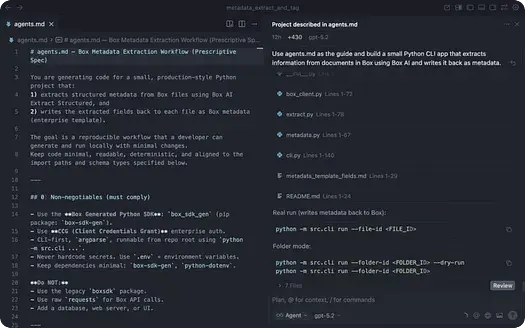
プロジェクトのレイアウト
プロンプトが完了すると、リポジトリには動作するプロジェクトが追加されます。
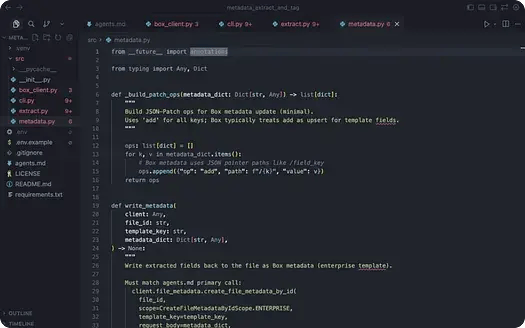
プロンプト実行後のリポジトリは次のようになります。
各モジュールには1つの責任があります。あるモジュールは環境の読み込みとCCG認証を処理し、別のモジュールは、構造化 (抽出) と正規化を担当して、さらに別のモジュールはメタデータをBoxに書き戻します。その後、CLIがこれらすべてをつなぎ合わせます。
このような分離により、コードの推論は容易になり、一括処理は単一ファイルパス上の薄いレイヤーとなります。
CLIを設定して実行する
プロジェクトができたので、他の小さなPythonツールと同じように実行できます。
仮想環境を作成して依存関係をインストールする
依存関係の表面積は意図的に小さくなっており、Box Generated Python SDKとpython-dotenvだけです。
次に、例の環境ファイルをコピーします。
Fill in your Box credentials (BOX_CLIENT_ID, BOX_CLIENT_SECRET, BOX_ENTERPRISE_ID). You can also set defaults for the metadata template key, scope, and AI model if you want to avoid passing them on every run.
Boxの資格情報 (BOX_CLIENT_ID、BOX_CLIENT_SECRET、BOX_ENTERPRISE_ID) を入力します。また、毎回実行するたびに渡すのを回避したい場合は、メタデータテンプレートキー、スコープ、AIモデルのデフォルト値も設定できます。
抽出ワークフローを実行する
環境が構成されたら、フォルダのすべてのドキュメントに対して抽出ワークフローを実行できます。
CLIは、クライアント資格情報許可を使用して認証し、フォルダ内のファイルを反復処理し、Box AIを使用して構造化フィールドを抽出し、それらの値を各ファイルにメタデータとして書き戻します。
実行が進むにつれて、ステップごとにラベルが付いた出力が表示されます。これには、ファイルごとのステータスや途中で発生したエラーが含まれます。
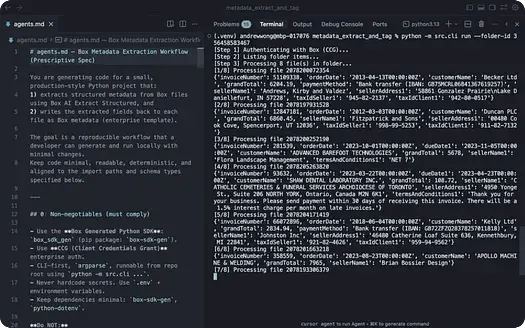
各ファイルは独立して処理されます。1つのファイルでエラーが発生しても実行は停止しません。そのため、品質や形式が異なるドキュメントが混在する実際のフォルダに適しています。
内部では、すべてのファイルが抽出→正規化→書き込みという同じフローに従っています。フォルダ実行は、その基本処理に基づいた調整にすぎません。
重要なポイント
この機能を作成した後に指摘しておくべきことがいくつかあります。
- リポジトリで具体的な内容が保持されているため、短いプロンプトで機能します。
- agents.mdは、実装の詳細ではなく、構造やインターフェースについて規定している場合に最も効果を発揮します。
- ここでの再利用可能な基本処理は、抽出→正規化→メタデータ書き込みであり、それ以外はすべて調整です。
- 依存関係の表面積を小さくしておくと、このようなツールを信頼および共有しやすくなります。
このパターンはBoxまたはメタデータ抽出に限定されるものではありません。安定した中核と柔軟な入力を持つワークフローであれば、同じアプローチで効果を発揮できます。制約をリポジトリに含めることで、再生成、レビュー、進化が可能になり、アシスタントはより信頼性の高い協力者となります。
次のステップ
ここからは、選択的書き込み、CSVの要約、再試行ロジック、より深い検証など、実用的な方法で簡単にCLIを拡張できます。重要なのは基盤が安定していることです。
リポジトリがその内容を把握すれば、AIにはほとんど何も指示する必要がなくなります。