
検索拡張生成 (RAG) は、生成AIモデルをドキュメントストアの外部のナレッジで補完する一般的な手法です。モデルは、内部のトレーニングデータのみを使用するのではなく、ナレッジベースから関連するコンテンツ (チャンク) を検索し、それを使用して、より正確かつ最新の応答を作成します。
コンテキスト検索は、このプロセスを強化するものです。これにより、検索ステップ自体で追加のコンテキストが考慮されます。そのコンテキストがデータ (チャンクの元になるドキュメントなど) から来ているか、ユーザーの状況 (最近のクエリやプロファイルなど) から来ているかは関係ありません。このブログでは、コンテキスト検索とは何か、それがRAGシステムにとってなぜ重要なのかを説明します。今後のブログでは、コンテンツソースとしてBox、ベクトルデータベースとしてPineconeを使用してコンテキスト検索パイプラインを作成する例を説明し、実装方法を紹介する予定です。
コンテキスト検索とは
コンテキスト検索とは、すべてのクエリやドキュメントを別個に扱うのではなく、コンテキストを考慮して情報を取得することを意味します。従来のRAGでは、ドキュメントはチャンクに分割され、インデックスが作成されます (多くの場合、セマンティック検索のベクトル埋め込みとして、BM25などのキーワードインデックスと組み合わせられる場合があります)。この基本的な手法は、チャンクに背景のコンテキストが欠けている場合に失敗する可能性があります。
例えば、チャンクが会社や期間には言及せず、「収益は前四半期比で3%増加しました」と述べているとします。チャンク自体があいまいであるため、標準的なRAGシステムでは、「ACME Corpの2023年第2四半期の収益成長率」に関する質問についてこのチャンクを検索するのに苦戦する可能性があります。コンテキスト検索では、チャンクまたはクエリプロセスに追加のコンテキストを組み込むことで、この問題に対処します。目標は、関連するドキュメントだけでなく、ユーザーのニーズに関連し、かつコンテキスト的に適切なドキュメントを検索することです。
コンテキスト検索の一般的な形式には以下の2つがあります。
- コンテンツチャンクのコンテキスト化: このアプローチでは、インデックスを作成する前に、各ナレッジチャンクに情報を追加して強化します。例えば、Anthropicの手法では、埋め込みを生成したりBM25インデックスを作成したりする前に、各チャンクの前に説明文を追加します (例: テキストの前に「このチャンクはACME Corpの2023年第2四半期のSECファイリングのものです…」と追加する)。そうすることで、チャンクのベクトル表現では、他の方法では失われる重要なコンテキストが伝達されます。ユーザーのクエリがエンコードされ、これらのベクトルと照合されると、追加のコンテキストにより、チャンク単体ではあいまいな場合でも、システムは適切な情報を見つけることができます。このコンテキスト埋め込み手法は、キーワードの完全一致検索用のContextual BM25インデックスと組み合わせることで、検索の成功率を劇的に向上させます。
- コンテキストに対応したクエリ実行: このアプローチでは、ユーザーまたはセッションに関する外部のコンテキストシグナルを使用して検索ステップを調整します。このシステムは、クエリテキストだけでなく、ユーザーの過去のクエリ、プロフィールや権限、クエリを実行した時間や場所、その他のドメイン固有の手がかりなどの要素も考慮します。例えば、ユーザーが特定のトピックに関するフォローアップの質問を何度も行っている場合、検索モジュールは、そのトピックに関連したドキュメントを優先するよう、結果を改善したり結果にフィルタをかけたりできます。これにより、複数回のやり取りを含む会話の継続性が確保され、無関係な結果や反復する結果を回避できます。実際には、コンテキストマネージャコンポーネントは、検索インデックスに到達する前にフィルタを追加したり、特定のスコアを引き上げたりすることで、未加工のクエリを変換できるため、ユーザーの状況をより正確に反映したドキュメントを検索でき、ユーザーに合ったタイムリーな回答が得られることにつながります。
上記の手法のいずれかまたは両方を使用することで、コンテキスト検索は、基本的なRAGパイプラインを、ニュアンスを理解するよりスマートなシステムに拡張します。検索段階は、キーワードや意味論的類似性のブラインドサーチだけでなく、どの関連情報が取得するのに最も適しているかを判断できる、コンテキストを考慮した操作にもなります。
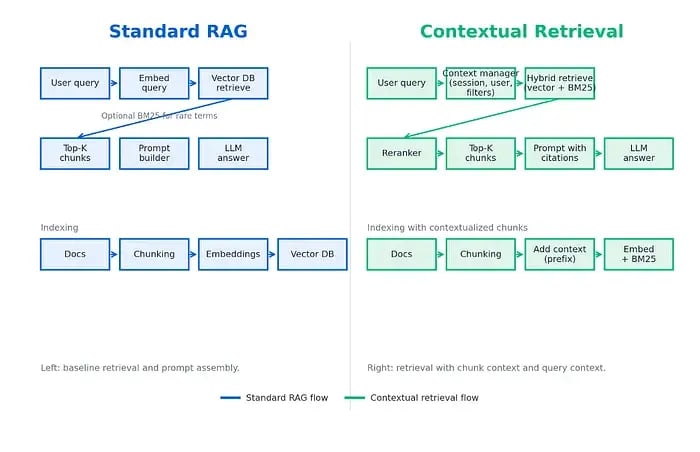
標準的なRAGワークフローとコンテキスト検索
従来のRAGシステム (左) で、クエリは埋め込みに変換され、ベクトルデータベースからチャンクを取得するのに使用されます。場合によっては、キーワードインデックス (BM25) が完全一致検索に使用されることもあります。コンテキスト検索 (右) では、追加のコンテキストが導入されています。これには、インデックス作成前に各チャンクにドキュメントコンテキストを追加したり、クエリ実行時にユーザーコンテキストを適用したりすることが含まれます。その結果、生成モデルに渡される情報をより正確に選択できるようになります。
コンテキスト検索が重要な理由
単純な検索戦略は、情報の見逃しや誤った回答につながる可能性があります。RAGシステムの精度や堅牢さを高め、ユーザーを意識したものにするため、コンテキスト検索は重要です。
- 精度の向上: 主要なコンテキストを保持することにより、システムは適切なデータをより頻繁に取得します。研究者は、(埋め込みとBM25の両方で) チャンクにコンテキストを追加すると、検索の失敗率がほぼ半減することに気付きました。言い換えれば、AIがナレッジベースに存在する回答を見逃す可能性がはるかに低くなるということです。生成モデルが正しい事実に基づいて動作するため、生成モデルからの応答の精度が高まることに直接つながります。
- 関連性と継続性の向上: コンテキスト検索では、ユーザーの状況を理解することが可能になり、質問している人、すでに閲覧した内容、質問したタイミングに基づいて結果を調整できます。例えば、開発者がQ&Aセッションで2つ目の質問を行った場合、システムが最初の質問の内容を把握していればより効率的に回答できます。その後もAIは、同じ内容を繰り返したり、トピックからはずれたりせずに、以前のコンテキストに基づく情報を提供します。これにより、さらに自然な会話のエクスペリエンスが実現し、ユーザーの満足度が高まります。
- 曖昧さと特異性への対処: クエリに固有の用語、コード、または参照が含まれている場合、ハイブリッド手法 (セマンティックベクトルと語彙検索の組み合わせ) を利用すれば何も見逃すことはありません。コンテキスト検索では、多くの場合、このハイブリッド検索に加え、コンテキストから得られる追加の手がかりを利用するため、特異性の高い質問 (サポートデータベース内のエラーコード「TS-999」など) でも完全一致を検出します。同様に、広範な質問の場合は、最も関連性の高いコンテキストに絞り込まれた結果が取得されます (例えば、ユーザーのロケールが判明している場合は、地域固有のドキュメントを表示します)。
- 大規模なナレッジベースに対する拡張性: ドキュメントコーパスが大きくなるにつれて、すべてをプロンプトに詰め込むことは現実的ではなくなります。コンテキスト検索では、プロンプトのサイズを大きくすることなく、応答の関連性を維持するための拡張性に優れた方法を提供します。候補ドキュメントをスマートに絞り込むことで、関連のないテキストでモデルに負荷をかけることを回避できるため、企業は、大規模なナレッジベースをLLMに接続し、焦点を絞った回答を取得することができます。実際、コンテキスト検索は、ノイズを減らして重要なことに焦点を絞るため、ClaudeやGPTなどのモデルで大規模な外部データを効率的に使用するための1つの鍵となります。
コンテキスト検索は、生成AIの導入をより正確かつコンテキストを意識したものにするため、従来のRAGが抱える「コンテキスト喪失」の問題を解決し、実際のタスクでのパフォーマンスを向上できます。
コンテキスト検索の仕組み
コンテキスト検索を実装するには、新しいステップと考慮事項を追加して標準的なRAGアーキテクチャを拡張する必要があります。内部でどのように機能するかを詳しく見てみましょう。
- ドキュメントの処理とインデックス作成: どのRAGの設定でも同様ですが、まず、ドキュメントをチャンク (段落やセクションなど) に分割し、チャンクごとにベクトル埋め込みを作成します。これらの埋め込みでは、意味論的意味を捉えます。コンテキスト検索では、このステップを変更します。コンテンツのコンテキスト化アプローチを使用する場合、埋め込み前に追加のコンテキストのテキストで各チャンクを拡張します。このコンテキストのテキストは、ドキュメントのタイトル、セクションの見出し、またはAIが生成したチャンクのソースの要約から得ることが可能です。また、コンテキストで拡張された同じチャンクは、完全一致検索用にキーワード検索エンジン (BM25を使用するwhooshやElasticSearchなど) でインデックスも作成されます。その結果、ベクトルインデックスと (オプションで) BM25インデックスが作成され、各エントリは未加工のチャンク単体よりも豊富な情報を伝達します。
- 例: 未加工のチャンクが「収益は前四半期比で3%増加しました」となっていて、ドキュメントから、2023年第2四半期のACME Corpに言及していることがわかるとします。そのコンテキストを先頭に追加するため、保存されるテキストは「このチャンクは、ACME Corpの2023年第2四半期報告書から取得したものです。収益は前四半期比で3%増加しました。」となります。ベクトルに埋め込まれたこのチャンクは、ベクトル空間においてACMEの2023年第2四半期の収益に関するクエリに近くなり、BM25で「ACMEの2023年第2四半期の収益」を検索してもこのチャンクがヒットします。コンテキストがなければ、セマンティック検索もキーワード検索もそれを確実に見つけることはできないでしょう。
- コンテキストを含むクエリの形成: ユーザーまたはセッションのコンテキストを使用する場合、システムは、受信したクエリを変換するか、検索パラメータを調整します。これは、コンテキストマネージャコンポーネント内で、未加工のクエリとコンテキスト (ユーザーID、場所、時刻、最近のクエリなど) を受け取り、変更されたクエリやフィルタの指示を生成することで可能となります。
例えば、ユーザーがEUにいることを認識している場合、コンテキストマネージャは、ヨーロッパのタグが付いたドキュメントのみを検索するように「AND region:EU」などのフィルタを追加する場合があります。また、これによりユーザーの業界や過去の興味に合致するドキュメントの関連性スコアが高まる場合もあります。ベクトル検索では、コンテキストの特徴を考慮するために、コンテキストベクトルを追加したり、類似性スコアリング関数を調整したりすることが必要になる場合があります。その結果、コンテキスト認識がすでに組み込まれているクエリが検索モジュールに渡されます。 - ハイブリッド検索 (セマンティック + 語彙): 検索ステップでは、ベクトル類似検索と語彙検索を組み合わせたハイブリッド検索戦略がよく使用されます。セマンティック検索 (埋め込みを使用) では、文言が異なっていても、クエリに概念的に関連するコンテンツを検出します。語彙検索 (BM25などを使用) では、クエリに珍しいキーワード、ID、またはフレーズが含まれている場合、それらの用語が見落とされることはありません。コンテキスト検索はここで真価を発揮します。つまり、コンテキストで拡張されたチャンクによってセマンティック検索の精度が向上するほか、コンテキストからのメタデータやタグ (ドキュメントソース、日付、作成者など) を語彙検索のフィルタとして使用できます。このシステムは、両方の手法の結果をマージして重複を削除するため、関連性が高く、かつコンテキストに適切に適合するチャンク候補のリストが示されます。
- 再ランク付けとフィルタ: 最初の検索後、多くのシステムでは再ランク付け (リランカー) モデルまたは追加のフィルタが適用されます。再ランク付けは、コンテキスト検索と組み合わせた場合に特に効果的です。学習済みリランカーモデルは、クエリとチャンク候補を受け取り、そのチャンクが特定の質問にどの程度適切に回答しているかを評価することができます。候補にはすでにコンテキストが備わっているため、リランカーはより多くの情報に基づいた判断を下すことができます。Anthropicは、コンテキスト検索に再ランク付けステップを追加したことで最大の利益が得られ、ベースラインと比較して検索の失敗が67%減少したことを報告しました。実際には、トランスフォーマーベースのクロスエンコーダをリランカーとして使用して、上位100件の結果から上位10件または20件を選別することで、最も関連性が高く、コンテキストに合致したコンテンツのみが最終段階に進むようになります。
- 回答生成: 最後に、top Kで検索されたチャンク (コンテキストは保持した状態) は、生成AIモデルに対するユーザーのクエリプロンプトに付加されます。その後、モデルは独自のナレッジと提供された検索コンテキストの両方を使用して回答を生成します。これまでのすべてのステップにより、モデルは正しいコンテキストを「ベース」としています。トピックに沿っているだけでなく、ユーザーのクエリのニュアンスにも特有な情報を参照します。これにより、ハルシネーションが減り、回答にドキュメントの詳細な事実を含めることが可能になります。ユーザーは、理想的には検索したソースを引用するか、少なくともそれらと合致する応答を受け取ります。
このパイプライン全体を通じて、コンテキスト検索がもたらす主な違いは、各ステージでコンテキストが利用される点です。つまり、チャンクはソースのコンテキストを伝達し、クエリはユーザーまたはセッションに関するコンテキストを伝達します。実装はさまざまで、1つの側面 (例: チャンクのコンテキスト化のみ、ユーザーに配慮したフィルタのみ) に重点を置くものもありますが、最も重要な原則は同じです。検索を一面的な検索のように扱わないことで、AIに渡される情報の質を大幅に高めます。
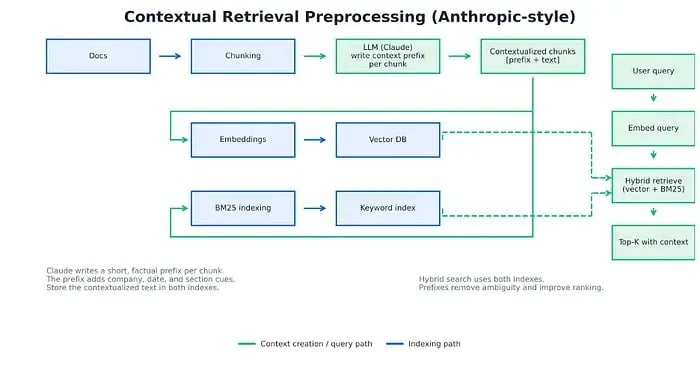
コンテキスト検索の前処理 (Anthropicの手法)
この図では、LLM (Claude) が各ドキュメントチャンクの簡単なコンテキストの要約を生成しており、その要約はその後チャンクテキストの先頭に追加されます。このような「コンテキスト化されたチャンク」は、ベクトルデータベースとBM25インデックスに格納されます。本来は暗に含まれていた会社、日付、その他重要な詳細がチャンクによって明確になるため、クエリ実行時に、システムは非常に精度の高い結果を取得できます。
次のステップ
コンテキスト検索を扱うリソースは数多く存在します。ここでの説明だけに留まらず、上記のアプローチや手法をより詳細に調査して、自分のユースケースに最も適した選択肢を判断してください。1つの方法ですべてのケースに対応できるわけではありません。データのコーパスに対する労力や複雑さによって成果も変わってくるため、バランスを取ることが重要です。
今後のブログでは、Box APIとPinecone APIを使用してAnthropic版のコンテキスト検索を実装する例を紹介する予定です。そこでは、Boxからコンテンツを取得してチャンクに分割した後、LLMを使用してチャンクとドキュメント全体の両方を送信し、埋め込む前にチャンクの先頭に追加されるコンテキストステートメントを生成する方法を説明します。