
ドキュメントからのメタデータの抽出は、一般的なタスクです。Boxでは、ID、請求書、契約書、フォームなどのメタデータが検索、自動化、リテンション、下流のワークフローの基盤としてよく使用されています。しかし、このようなデータを大量に入力するには時間がかかることがあります。
この記事では、Boxフォルダから直接ファイルを読み込み、Box AIを使って構造化された値を抽出し、それらをBoxメタデータとして書き戻すテンプレート駆動型のエージェントスキルについて説明します。なお、これらのファイルは、検索、自動化、下流のワークフローを引き続き実行する記録システムとしてBox内に保持されます。
エージェントスキルとは
エージェントスキルとは、エージェントが何ができるかを定義するための移植可能な、宣言的な仕組みです。
ワークフローを長いプロンプトでコード化したり、複数のプロジェクトで同じ指示を実行したりするのではなく、エージェントスキルでは「Boxファイルからメタデータを抽出して書き戻す」などの機能を再利用可能な定義 (SKILL.md) としてパッケージ化します。この定義を、エージェント環境にインストールできます。
Boxのような実運用されているシステムとやり取りできるよう、このデモで使用するスキルではMCP (Model Context Protocol) を利用しています。MCPはファイル、メタデータ、Box AIを、エージェントが直接呼び出せるツールとして公開します。これにより、ワークフローを宣言的に定義でき、手作業でAPIクライアントを記述したり接続リクエストを行ったりする必要がなくなります。
実際には、そのようなワークフローは一度だけ構造化された方法で定義されます。スキルは、MCPやBox AIなどのツールの調整を担います。同じ機能を複数のフォルダ、スキーマ、プロジェクトに対して再利用できます。
インストールしたスキルは、多くの場合、以下のように1つのコマンドのような形で使用します。
エージェントがこの調整を担い、スキルによってルールが定義されます。
このことがメタデータワークフローで重要である理由
Boxでは、メタデータを使って構造化フィールド (メタデータテンプレートで定義) をファイルやフォルダに関連付けることができます。構造化フィールドの例としては、請求書番号、ベンダー、有効期限などがあり、APIを通じて検索、自動化、アクセスが可能な主要データとして扱われます。
メタデータはスキーマ駆動型であるため、抽出ワークフローは繰り返しが可能なものとして作成される傾向があります。ターゲットファイルを特定し、既知の一連のフィールドを抽出し、既存データを上書きせずに安全に値を書き戻すという、同じ手順が毎回適用されます。
そのため、メタデータ抽出はエージェントスキルに最も適した処理と言えます。エージェントスキルとMCPを組み合わせることで、一度コード化すれば (APIのグルーコードを作成しなくても)、複数のフォルダやドキュメントタイプ、メタデータテンプレートに対して再利用できます。テンプレートによって抽出する対象を定義し、スキルによって安全に抽出する方法を定義し、MCPによってBoxとのやり取りをバックグラウンドで処理します。
メタデータが検索、自動化、下流システムの基盤となるため、結果としてワークフローを再利用しやすくなり、安全な再実行が可能になり、理解もしやすくなります。
アーキテクチャの概要
大まかに言うと、ワークフローは次のようになります。
エージェントはプロセスを調整し、Boxは引き続き記録システムとして機能し、MCPはエージェントが呼び出せるツールとしてBoxの機能を公開します。
前提条件
スキルを実行する前に、以下のものを準備してください。
-
Cursorで動作するBox MCPサーバー (ツールが表示可能)
-
Boxメタデータテンプレート (template_keyを推奨)
-
ファイルが保存されているBoxフォルダ (最上位のみ)
エージェントスキルのインストール
リポジトリのルートから:
インストール後にCursorを再起動してスキルを読み込みます。
スキルの定義 (SKILL.md)
ワークフローの動作はSKILL.mdで宣言的に定義されています。ファイル全体については説明しませんが、スキルの主要な技術的特性を以下に示します。
- テンプレート駆動型抽出: このスキルは (キーまたは名前で指定された) Boxメタデータテンプレートを入力として受け取り、そのスキーマを使って、抽出するフィールドを正確に決定します。ドキュメント固有のロジックはハードコードされません。
- MCPベースのBoxアクセス: Boxとのすべてのやり取り (フォルダコンテンツのリストの取得、Box AIによるコンテンツ抽出、メタデータの読み取りまたは書き込み) はBox MCPツールを通じて実行されます。カスタムAPIクライアントやグルーコードは不要です。
- メタデータの安全な書き込み: スキルはメタデータを書き込む前に、既存のメタデータインスタンスがあるかどうかを確認し、現在空のフィールドのみに入力します。既存の値は、決して上書きされません。
- Boxネイティブ処理: ドキュメントはワークフローが終了するまでBox内に残ります。ファイルはダウンロードされず、ローカルで保持されることもありません。Boxは引き続き、コンテンツとメタデータの両方の記録システムとして機能します。
スキル定義全体については、GitHubでご確認ください。この投稿にも、参照用としてSKILL.md全体を掲載しています。
Cursorでのスキル実行
インストール後は、Cursorチャットから直接スキルを起動します。
まずはdry runから
以下にようにして、コードを一切作成しなくても、アクセスと抽出のロジックを検証できます。
想定される動作:
- Box MCPツールが呼び出されます (ファイルのリスト取得、テンプレートの読み込み、値の抽出)。
- Cursorは、想定される書き込み内容の概要を返します。
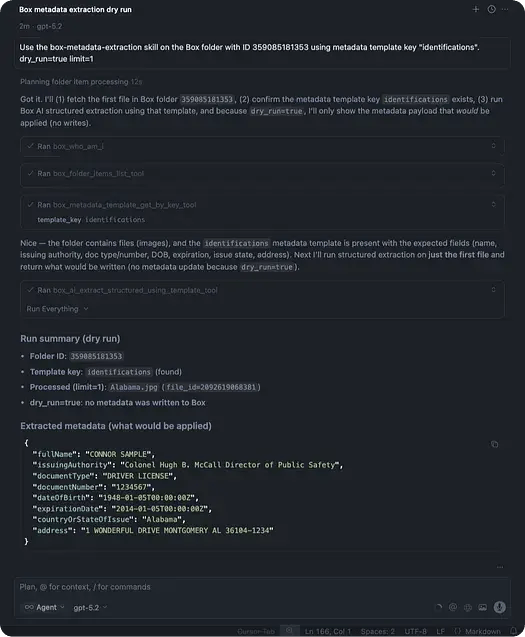
単一のファイルに対するメタデータの書き込み
dry runの結果が正常であれば、以下を実行します。
これによりフォルダ内にある1つのファイルについてのみメタデータが更新されるため、大規模に実行する前に動作を検証する目的に役立ちます。
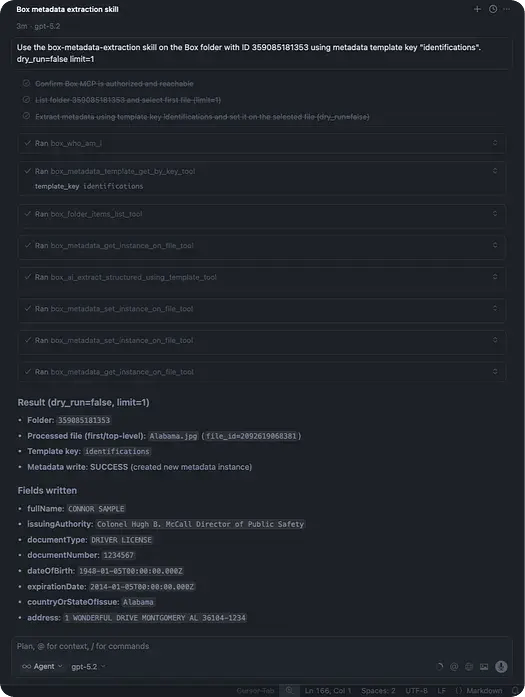
単一のファイルで結果を検証した後は、limitパラメータをはずしてワークフローをフォルダ全体に対して実行するだけです。同じ抽出および書き戻しのロジックが、最上位のファイルすべてに一貫して適用されます。
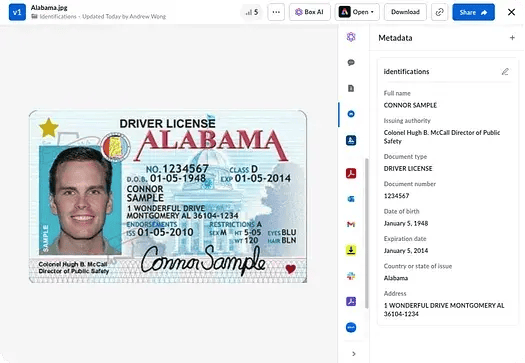
Boxでの結果の確認
Boxで処理済みファイルを開いて [メタデータ] パネルを展開します。次の項目が表示されます。
- 適用されたメタデータテンプレート
- 抽出された入力済みフィールド
- 値のない空白のままのフィールド
- 変更されなかった既存の値
スキル定義全体 (SKILL.md)
これまでの説明で使用したSKILL.mdの全体を以下に示します。
スキルを使用する際に、上に示した定義を編集する必要はありません。ここでスキル定義全体を紹介したのは、動作のわかりやすさと、適応しやすさのためです。
テンプレート駆動型スキルが再利用しやすい理由
スキルをインストールした後、入力 (ファイルを含むBoxフォルダとスキーマを定義するメタデータテンプレート) を変更するだけで、同じワークフローを再利用できます。
このスキルはテンプレート駆動型なので、事前にドキュメントタイプについて知る必要はありません。メタデータテンプレートによって、抽出されるフィールドが決定されます。対象のファイルが請求書、契約書、ID、その他の文書であっても、スキルによって同じ安全な抽出ロジックが適用されます。
これにより、複数のチームやユースケースでワークフローを簡単に再利用できます。同じスキルを異なるフォルダやテンプレートに適用できます。プロンプトを書き直したり、ロジックを複製したり、ドキュメント固有のバリエーションを作成したりする必要はありません。動作は一貫しています。変わるのは入力だけです。
リポジトリと次のステップ
GitHubリポジトリ: https://github.com/box-community/box-mcp-agent-skill-metadata-extraction
次のステップとして、以下のことができます。
- メタデータを記述する前にレビューや承認のステップを追加する
- 深い階層構造に対応するためにフォルダ再帰を導入する
- このスキルと他のスキルを連鎖させる
エージェントスキルを使用すると、繰り返し可能なコンテンツワークフローを簡単に再利用可能な構成要素へと変えることができます。特にBox MCPやBox AIと組み合わせた場合、その効果を実感できます。